* 인덱스
- 데이터 빠르게 찾을 수 있는 수단
- 테이블에 대한 조회 속도 높여 주는 자료구조
- 테이블에서 자주 사용되는 컬럼 값 빠르게 검색 가능토록 색인 만들어 놓은 형태
- 과다한 인덱스 생성은 DB 공간 많이 차지하며 Table Full Scan보다 속도가 느려질 수 있음
- 테이블 데이터 삽입, 삭제, 변경 수행하는 DML 작업 시 성능 떨어짐
* 인덱스 구조와 장점
- 인덱스 구성 위해 가장 많이 사용하는 검색 트리 : B-Tree 구조
- DB 성능 향상 위한 DB 튜닝 수단으로 가장 일반적인 방법
- 장점
- 데이터 검색 위한 SQL 구문 변경 않아도 검색 성능 개선
- 데이터 검색하기 위한 별도 객체로서 테이블 데이터에 영향 주지 않음
* 인덱스 사용
- 테이블의 특정 레코드 위치 알려주는 용도로 사용. 이러한 인덱스는 자동으로 생성되지 않으며, 별도의 DDL 이용하여 생성
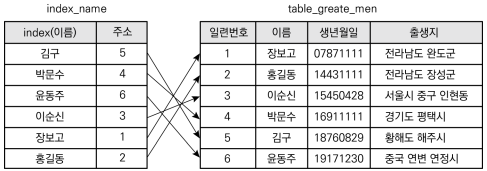
- 기본키 생성 시 추가한 컬럼은 기본키 생성할 때 자동으로 기본키 인덱스 생성됨
- 예 : 일련번호를 기본키로 하는 경우, 일련번호에 대한 인덱스는 자동으로 생성되며 생년월일, 이름, 출생지 기준으로 하는 인덱스는 자동으로 생성 안됨
- 인덱스 생성되어 있는 테이블 컬럼을 검색 조건으로 사용한다면 일부분을 검색(Range scan)하여 데이터 빠르게 검색 가능
- 예 ) 기본키 인덱스가 생성된 일련번호 검색 시 인덱스 데이터 주소(Row_id) 통해 바로 테이블 해당 일련번호 튜플 검색
- select * from table_great_men where 일련번호=1;
- 예 ) 기본키 인덱스가 생성된 일련번호 검색 시 인덱스 데이터 주소(Row_id) 통해 바로 테이블 해당 일련번호 튜플 검색
- 인덱스 없는 '이름'을 비교한다면 해당 테이블 '이름' 컬럼에 인덱스가 없기 때문에 테이블 전체 내용 검색
- select * from table_great_men where 이름='이순신';
- 조건절에 '='로 비교되는 컬럼 대상으로 인덱스 생성하면 경우의 수 적어 검색 속도 높일 수 있음. 인덱스는 자동으로 생성되지 않기 때문에 사용자가 자주 사용하고 테이블의 경우 수가 적은 데이터 대상으로 인덱스 생성해야 함
* 인덱스 종류
| 유형 | 설명 |
| 순서 인덱스 (Ordered) |
- 데이터가 정렬(Sorting)된 순서로 인덱스 생성 관리 - B-Tree 알고리즘 이용. 오름차순, 내림차순 지정 |
| 해시 인덱스 (Hash) |
- 해시함수에 의해 직접 데이터에 키 값으로 접근 - 데이터에 접근 비용이 균일. 행 양에 무관 |
| 비트맵 인덱스 (Bitmap) |
- 각 컬럼에 적은 개수 값이 저장된 경우 선택(OLAP성 업무에 적합) - 수정 변경이 적은 경우 유용(예 : 성별, 직급, 색상 등) |
| 함수 기반 인덱스 (Functional) |
- 함수 기반으로 사전에 인덱스 설정하면 인덱스 기능 및 속도 향상 - 예) CREATE INDEX IDX_EMP01_ANNSAL ON EMP01(SAL*12); |
| 단일 인덱스 (Simgled) |
- 하나의 컬럼으로만 인덱스 지정 - 업무적 특성에 의해 주로 사용되는 컬럼 하나인 경우 |
| 결합 인덱스 (Concatenated) |
- 복수개 컬럼 이용하여 인덱스 지정 - 동시에 WHERE 조건으로 사용되는 빈도 많은 경우 |
| 클러스터 인덱스 (Cluster) |
- 저장된 데이터 물리적 순서에 따라 인덱스 생성 - 특정 범위 검색 시 유리 (예:일자구간) |
320x100
'정보처리기사 > 필기' 카테고리의 다른 글
| [정보처리기사 필기 요약] 인덱스(INDEX) (3) (0) | 2021.03.03 |
|---|---|
| [정보처리기사 필기 요약] 인덱스(INDEX) (2) (0) | 2021.03.03 |
| [정보처리기사 필기 요약] 뷰(View) (0) | 2021.03.03 |
| [정보처리기사 필기 요약] 미들웨어 솔루션 (0) | 2021.03.02 |
| [정보처리기사 필기 요약] 데이터 명세화 (0) | 2021.03.02 |




댓글